머신러닝(2) Supervised 러닝 Data Preprocessing과 카테고리컬 데이터
앞에서 많이 언급되었지만 머신러닝을 하기 위해선 컴퓨터가 알수 있는 형태로 데이터를 주고 학습시켜야 한다. 컴퓨터가 알수 있는 형태로 데이터를 가공하는 기법이 Data Preprocessing(데이터 전처리) 과정이다.
Supervised 러닝에 Data Preprocessing에는 2가지 방법이 있다.
우선 데이터를 준비한다.
#데이터 파일에서 부르기
df=pd.read_csv('../data/Data.csv')
df
이제 전처리 하기 전에 NaN데이터를 없앤다. 머신러닝으로 학습할 데이터는 NaN값을 바꿔서 채우기 보다 삭제하는것이 낫다.
df=df.dropna()
df
학습시킬 데이터와 결과 데이터를 나눈다. 지도 학습에선 전에 언급했듯이 기존의 데이터가 있어야 한다.
#대소문자 구별 주의
#학습시킬 데이터 X로 지정
X = df.loc[ : , 'Country':'Salary' ]
#결과 데이터 y로 지정
y = df['Purchased']
X
y

다 나눴으면 이제 Data Preprocessing을 진행해보자
1) LabelEncodering
위에 데이터는 문자열 데이터여서 컴퓨터가 데이터를 학습하기 어려울 수 있다. 그래서 LabelEncodering 기법으로 전처리를 진행하면 문자열 데이터를 int로 바꿔준다. 바꾸는 순서는 알파벳 순으로 0,1,2이런식으로 진행된다.
# 데이터 전처리 라이브러리 import
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
from sklearn.compose import ColumnTransformer
# 1. 레이블 인코딩 하는 방법
encoder = LabelEncoder()
X['Country']=encoder.fit_transform(X['Country'])
X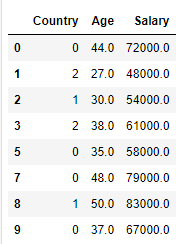
데이터가 문자열에서 int가 되었지만 카테고리컬 데이터여서 중복이 있어 머신러닝으로 학습하기 적절하지 않을수 있다.
2) OneHotEncodering
두번째는 카테고리컬 데이터의 중복 방지까지 해주는 방법이다. 카테고리컬 데이터를 자동으로 컬럼을 나누어 처리 해준다. 주로 카테고리컬 데이터에서 중복 데이터가 3개이상있을때 사용된다.
France Germany Spain
1 0 0
0 0 1
0 1 0
0 0 1
0 0 1
카테고리컬 데이터를 이런식으로 컬럼을 나눠서 바꿔준다.
#2. 원 핫 인코딩 하는 방법
# 원핫 인코딩으로 바꾸고 싶은 컬럼의 인덱스를 써준다.
#[0]이라고 써준다.
#만약에 원핫인코딩으로 바꾸고 싶은 컬럼이 여러개이면,
#리스트안에 인덱스만 써주면 된다. 예) [1,4,5]
#오타 주의
ct=ColumnTransformer([('encoder',OneHotEncoder(),[2])],remainder = 'passthrough')
#remainder passthrough 원핫인코딩이 아닌 컬럼들은 냅둬라!
#원핫인코딩 한 컬럼은 맨앞으로 빠진다.
X = ct.fit_transform(X)
X
위에서 보여준대로 데이터가 컬럼이 나눠져서 저장된다.
y데이터도 원핫인코딩이 되지만 카테고리컬 중복데이터가 2개 이므로 레이블 인코딩만 해주면 된다.
#인코더 함수 따로 지정
encoder_y = LabelEncoder()
y=encoder_y.fit_transform(y)
y
>>> array([0, 1, 0, 0, 1, 1, 0, 1])y도 바뀐걸 알수 있다.