데이터를 비교하려면 기본적으로 노멀라이징 시켜야 데이터끼리 비교할수 있다. 이과정으로 데이터 전처리라고 하는데
이 과정을 거치지 않으면 데이터의 불균형으로 인해 비교가 매우 어려워 질수 있다.
우선 표준화 정규화를 알아보자 표준화 정규화는 데이터 전처리기법중 하나로
표준화는 실수로 데이터를 표현하고
정규화는 0~1사이로 데이터를 표현한다.
우선 데이터를 불러온다.
#13번에서 본 서울지역 범죄현황 데이터를 활용한다.
crime_anal = pd.read_csv('new_crime_in_Seoul.csv', index_col=0)
crime_anal
from sklearn import preprocessing
# 1. 표준화 방법
from sklearn.preprocessing import StandardScaler, MinMaxScaler
s_scaler = StandardScaler()
X_scaled1 = s_scaler.fit_transform(crime_anal.loc[ : , '강간' : '폭력' ])
# 2. 정규화 방법
m_scaler = MinMaxScaler()
X_scaled2 = m_scaler.fit_transform(crime_anal.loc[ : , '강간' : '폭력' ] )
#정규화된 데이터를 다시 컬럼에 저장한다.
crime_anal.loc[ : , '강간':'폭력'] = X_scaled2
crime_anal
데이터가 0~1사이 데이터로 표준화 되어 있는 사실을 볼 수 있다. 이제 데이터를 비교할 준비가 거의 끝났다.
이제 차트를 그리고 상관계수를 구해서 데이터 간의 관계를 비교해보자
표준화 데이터를 CCTV 데이터랑 합친다.
#합칠 데이터를 불러온다.(전에 한 CCTV 데이터)
CCTV_result = pd.read_csv('../day12/CCTV_result', index_col= 0)
CCTV_result.rename(columns={'소계':'CCTV'}, inplace=True)
crime_anal[ ['CCTV', '인구수'] ] = CCTV_result[ ['CCTV','인구수'] ]
또한 컬럼을 종합 데이터로 2개 추가 한다.
crime_anal['범죄'] = crime_anal['강간'] + crime_anal['강도'] +crime_anal['살인']+ crime_anal['절도'] + crime_anal['폭력']
crime_anal['검거'] = crime_anal['강간검거율'] + crime_anal['강도검거율'] + crime_anal['살인검거율'] + crime_anal['절도검거율'] + crime_anal['폭력검거율']
crime_anal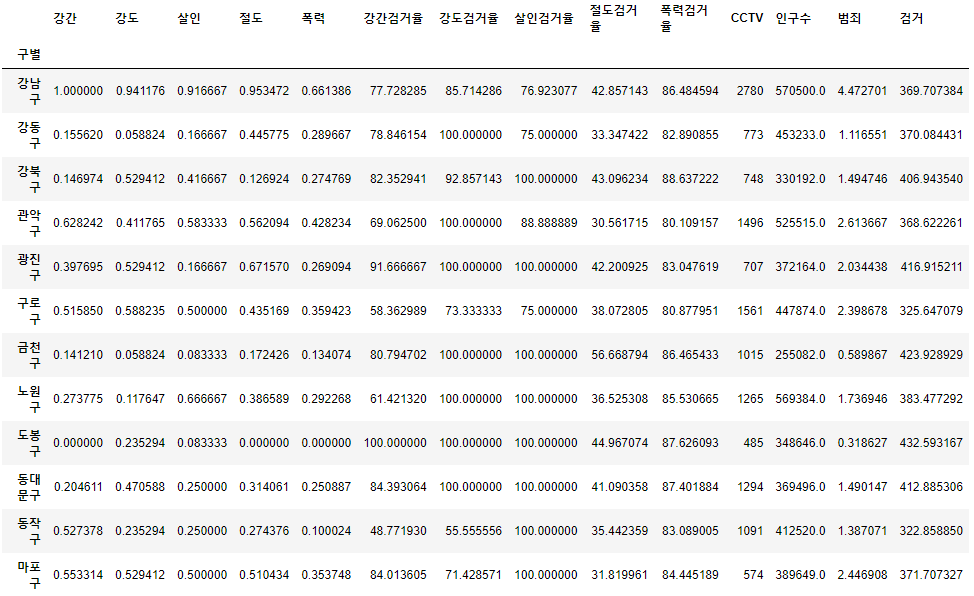
이제 비교 할 모든 데이터가 모였으니 2가지 방법으로 비교해 본다.
1.sb의 pairplot 으로 데이터 관계를 나타내세요(x_vars는 "인구수", "CCTV" 를, y_vars는 "살인검거율", "폭력검거율"로 pariplot을 나타내고, 연관성을 확인하세요)
sb(seaborn)라이브러리에 pairpolt함수는 산점도 차트를 여러개 그려 데이터의 관계를 비교한다.
#산점도를 그리고 선을 나타낸다. x값엔 인구수,CCTV컬럼 y값엔 살인검거율,폭력검거율
sb.pairplot(data=crime_anal,kind='reg',x_vars=['인구수','CCTV'],y_vars=['살인검거율','폭력검거율'])
plt.show()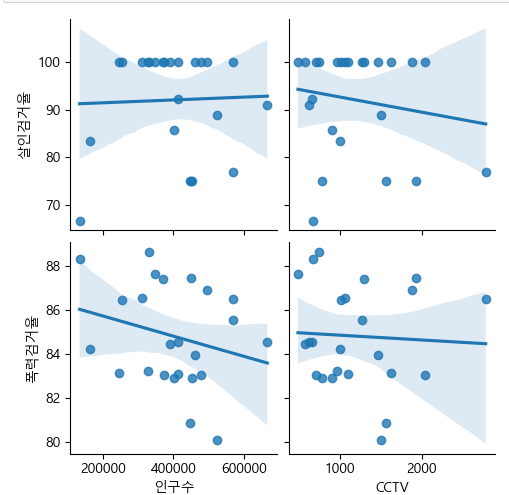
위그래프로 보아 인구수가 많을수록 폭력 검거율은 떨어지는걸 알수 있다.
2.sb.heatmap 을 이용해서 '강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율' 을 보여주세요. 단, '검거' 로 정렬한 데이터로 보여주세요.
히트맵을 활용하면 시각적으로 어디가 가장 검거율이 좋은지 알수 있다.
우선 비교를 하려는 데이터에서 비교를 하려는 컬럼만 잘라 저장한다.
#비교를 하려는 컬럼만 잘라 저장한다.
df1=crime_anal.sort_values('검거',ascending=False)
df2=df1.loc[ : ,'강간검거율':'폭력검거율']
df2
히트맵을 그려보자
#fmt에서 정수는 .0f
plt.figure(figsize=(10,8))
sb.heatmap(data=df2,cmap='RdPu',annot=True,fmt='.1f',linewidths=0.8)
plt.show()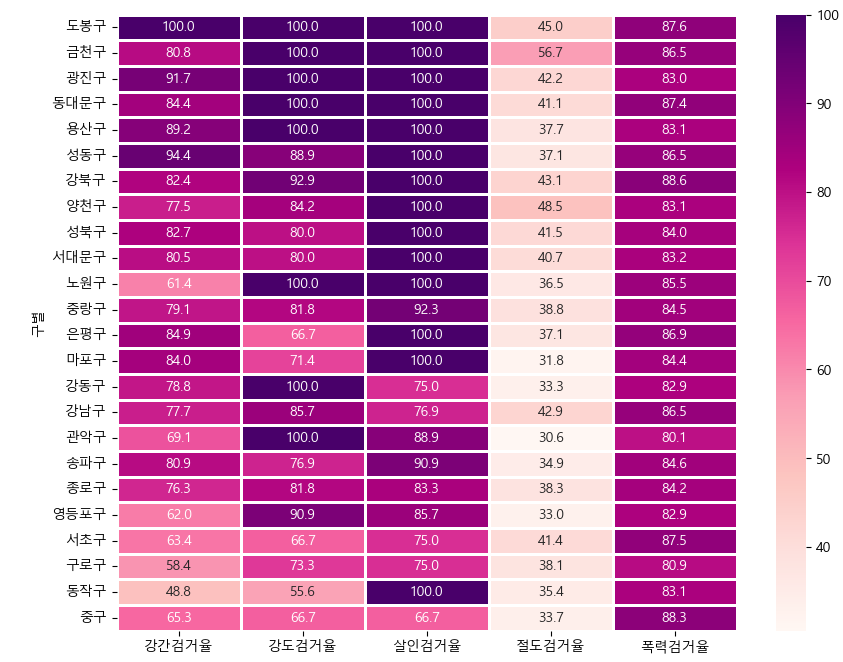
히트맵 결과 진한게 검거율이 좋은거고 도봉구가 가장 검거율이 좋은것을 시각적으로 알수있다.
'파이썬 함수' 카테고리의 다른 글
| 머신러닝(9) confusionmatrix 값 시각화 하기 (0) | 2022.12.02 |
|---|---|
| pandas 라이브러리(13) api 데이터 불러오기 (1) | 2022.11.30 |
| pandas 라이브러리(11) pandas 데이터 내에 문자열 슬라이싱 (0) | 2022.11.30 |
| pandas 라이브러리(10) 엑셀데이터 불러오기 (1) | 2022.11.30 |
| pandas라이브러리(9) 데이터 프레임에서 찾는값이 아닌걸 엑세스 할 경우 (0) | 2022.11.29 |