비어
있는 데이터(NaN)는 인공지능으로 예측할수 없다. 따라서 NaN을 처리하여
데이터 프레임으로 인공지능을 활용할수 있는 상태로 해야한다.
NaN을 처리하는데는 2가지 방법이 있다.
1. .dropna() 함수로 NaN을 삭제한다.
dropna()함수로 NaN를 삭제할때는 반드시 NaN가 들어는 행이나 열로
삭제된다. 물론 임계값을 설정하여 한행이나 열에 NaN값이 여러개 들어있는
경우만 삭제할수 있긴하다.
items2 = [{'bikes': 20, 'pants': 30, 'watches': 35, 'shirts': 15, 'shoes':8, 'suits':45},
{'watches': 10, 'glasses': 50, 'bikes': 15, 'pants':5, 'shirts': 2, 'shoes':5, 'suits':7},
{'bikes': 20, 'pants': 30, 'watches': 35, 'glasses': 4, 'shoes':10}]
df=pd.DataFrame(data= items2,index = ['store1','store2','store3'])
df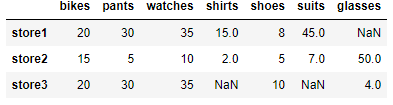
그림에 데이터에서 NaN값을 삭제해본다.
# 1. 삭제하는 전략
df.dropna()
NaN값이 들어있는 데이터가 삭제된걸 볼수 있다.
2. .fillna() 함수로 특정값으로 채운다.
fillna()함수로 NaN값에 특정값을 채울 수있다. 특정값은 fillna()의 괄호에 작성하면 된다.
#맨위에 데이터베이스를 쓴다.
# 2. 특정값으로 채우는 전략
df.fillna(0)
fillna() 함수로는 단순히 특정값 이외에도 특정 행열만 특정값을 채우거나
# 셔츠데이터의 비어있는 부분은 0으로 채운다.
df.loc[:,'shirts'].fillna(0)
# suits 와 glasses의 비어있는 데이터는 100으로 채운다.
df.loc[:,['suits','glasses']].fillna(100)

비어있는 데이터의 위아래나 좌우등의 데이터와 똑같은 값으로 채우거나
#데이터 프레임은 맨위에 있는걸 쓴다.
#위 행의 데이터로 채운다.
df.fillna(method= 'ffill',axis=0)
#forwardfill에 약자로 쓴다. 바로 윗행이라는뜻
#아래 행의 데이터 채운다.
df.fillna(method = 'bfill',axis=0)
#backwardfill에 약자로 쓰고 바로 아랫행이라는뜻

#맨위에 데이터 프레임을 쓴다.
#왼쪽 열의 데이터로 채운다.
df.fillna(method = 'ffill',axis=1)
#이번엔 앞쪽(왼쪽)열
#오른쪽 열의 데이터로 채운다.
df.fillna(method = 'bfill',axis=1)
#이번엔 뒤쪽(오른쪽)열

각 컬럼별 합계 평균 최대값 등으로 채울수 있다.
#데이터베이스는 맨위에 있다.
#각 컬럼별 평균으로 채우기
df.fillna(df.mean())
#각 컬럼별 최대값으로 채우기
df.fillna(df.max())

반응형
'파이썬 함수' 카테고리의 다른 글
| pandas 라이브러리(5) PANDAS OPERATIONS (0) | 2022.11.24 |
|---|---|
| pandas 라이브러리(4) 카테고리컬 데이터( Categorical Data) (0) | 2022.11.24 |
| pandas 라이브러리(2) 데이터프레임 컬럼 추가하기, 데이터프레임 불러오기 (0) | 2022.11.24 |
| pandas 라이브러리(1) pandas라이브러리 활용 (0) | 2022.11.24 |
| numpy 라이브러리(5) 2차원 배열 연산 (0) | 2022.11.23 |